About
MultiMT is a project led by Prof. Lucia Specia, funded by an ERC (European Research Council) Starting Grant. The aim of the project is to devise data, methods and algorithms to exploit multi-modal information (images, speech, metadata etc.) for context modelling in Machine Translation and other crosslingual and multilingual tasks. The project is highly interdisciplinary, drawing upon different research fields as such NLP, Computer Vision, Speech Processing and Machine Learning.
News
[24/07/2019] A paper on phrase localization without paired examples has been accepted for oral presentation at ICCV 2019!
[15/05/2019] Two long papers have been accepted at ACL 2019! One on evaluating the visual fidelity of image captions, another on distilling translations with images.
[10/04/2019] We have been awarded the best short paper at NAACL 2019!
[25/02/2019] A short paper has been accepted for an oral presentation at NAACL 2019!
[01/10/2018] The project and the team are moving to Imperial College London. More soon!
[01/09/2018] Pranava will be at BMVC 2018 in Newcastle upon Tyne.
[25/06/2018] The team is participating in a 6-week JSALT workshop on grounded sequence to sequence transduction. You can watch our final presentation here.
[29/05/2018] Pranava and Josiah will be at NAACL 2018. Please say hi and visit our talk (Sunday morning) and poster (Monday afternoon)!
[03/05/2018] Chiraag will be at LREC 2018. Please visit our poster!
[03/03/2018] Josiah and Pranava will be at the Conference for the European Network on Integrating Vision and Language (IVL 2018) in Tartu, Estonia (barring weather issues!). Come talk to us!
[01/03/2018] A short paper on ‘de-foiling’ foiled image captions accepted for an oral presentation at NAACL 2018!
[14/02/2018] A long paper on using explicit object detection outputs for image captioning accepted at NAACL 2018!
[20/12/2017] A paper on Multimodal Lexical Translation accepted at LREC 2018!
[07/09/2017] A paper on using speech information for NMT accepted at ASRU 2017!
[05/09/2017] Lucia, Pranava and Chiraag will be at WMT/EMNLP 2017 in Copenhagen. Please visit our poster for the WMT Multimodal MT shared task!
[01/09/2017] Lucia will be giving a talk on Multimodal Machine Translation at the MT Marathon in Lisbon on 1st Sept 2017. The slides are available here.
[08/07/2017] Our system paper for the WMT Multimodal Machine Translation Shared Task is available.
[16/06/2017] A paper on fine-tuning with auxiliary data accepted at Interspeech 2017!
[20/05/2017] A paper on investigating the contribution of image captioning for MMT accepted at EAMT!
Team
Members







Former Members


Publications
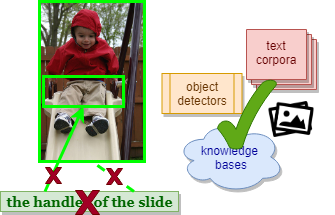
Phrase Localization Without Paired Training Examples
International Conference on Computer Vision (ICCV), 2019
How well can a system localize phrases in an image without using any paired training examples?
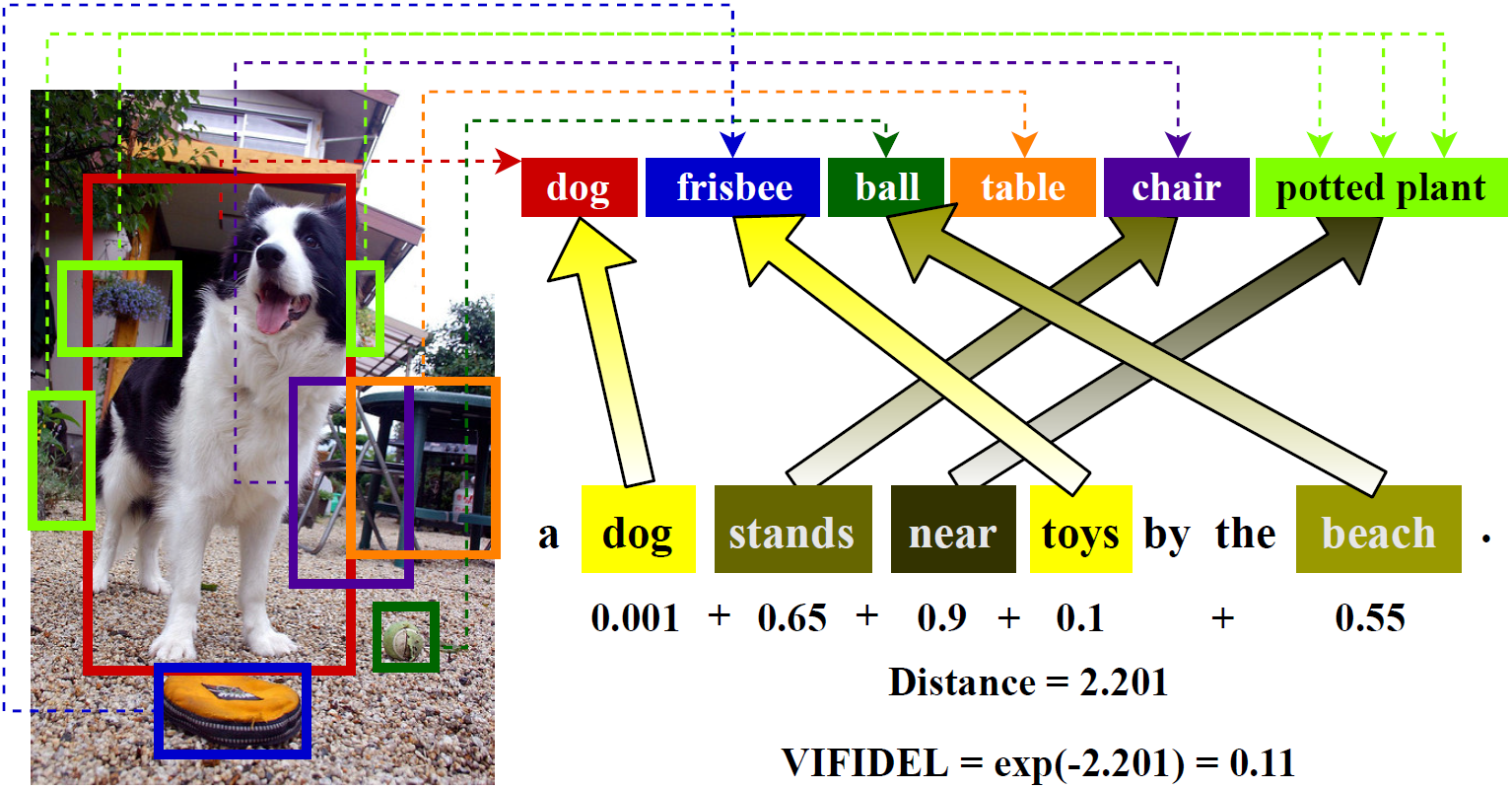
VIFIDEL: Evaluating the Visual Fidelity of Image Descriptions
Association of Computational Linguistics (ACL), Long Paper, 2019
Evaluating the faithfulness of a generated image description with respect to the content of the actual image. Can be used without reference descriptions.
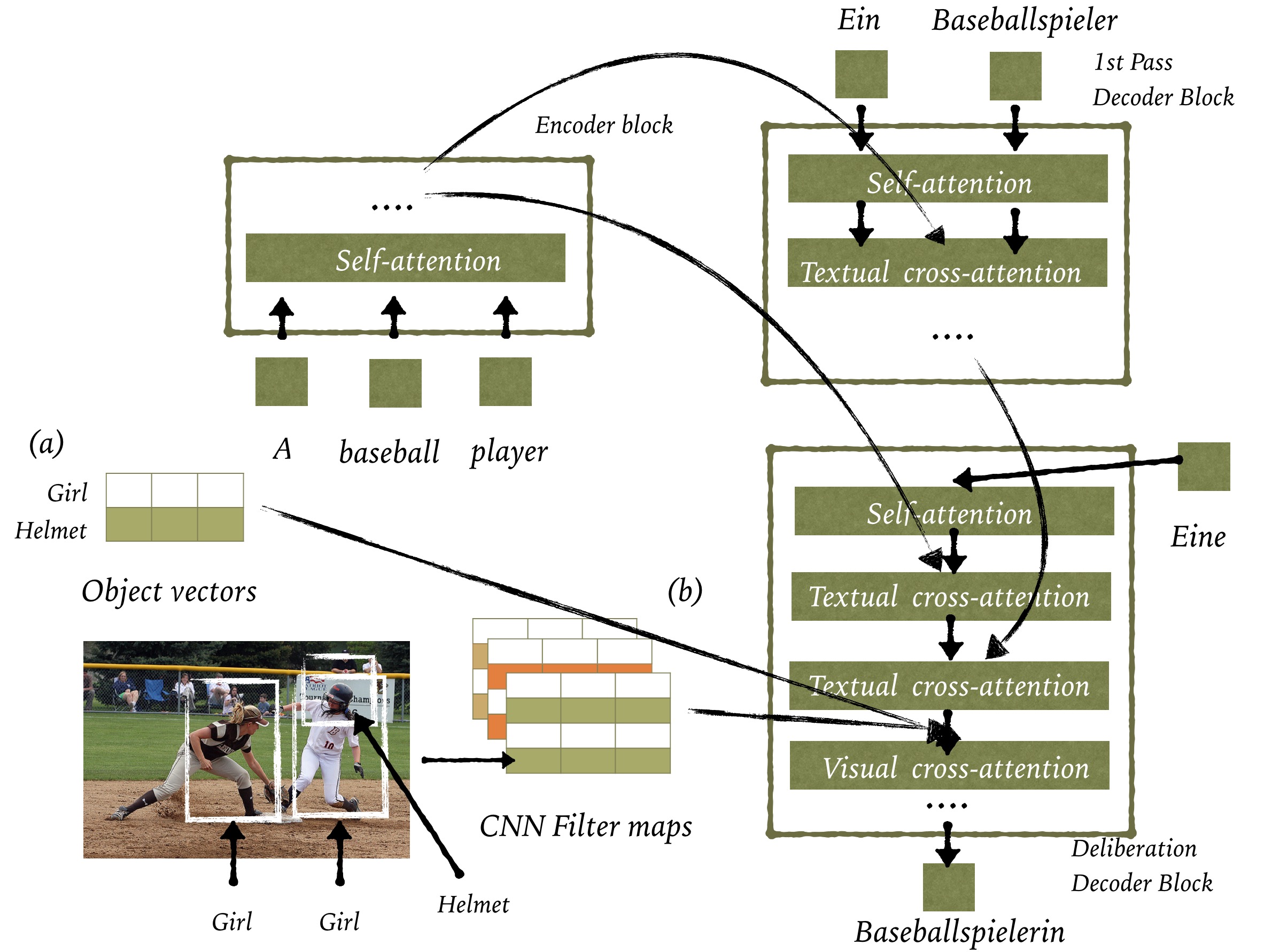
Distilling Translations with Visual Awareness
Association of Computational Linguistics (ACL), Long Paper, 2019
The approach is based on deliberation networks to jointly learn to generate draft translations and refine them based on left and right side target context as well as structured visual information.

Predicting Actions to Help Predict Translations
The How2 Challenge: New Tasks for Vision and Language @ ICML (workshop), 2019

Probing the Need for Visual Context in Multimodal Machine Translation
North American Chapter of the Association of Computational Linguistics: Human Language Technology (NAACL HLT), Short Paper, 2019
Best short paper
Grounded Word Sense Translation
Workshop on Shortcomings in Vision and Language @ NAACL-HLT, 2019

How2: A Large-scale Dataset for Multimodal Language Understanding
Visually Grounded Interaction and Language (ViGIL) @ NeurIPS, 2018
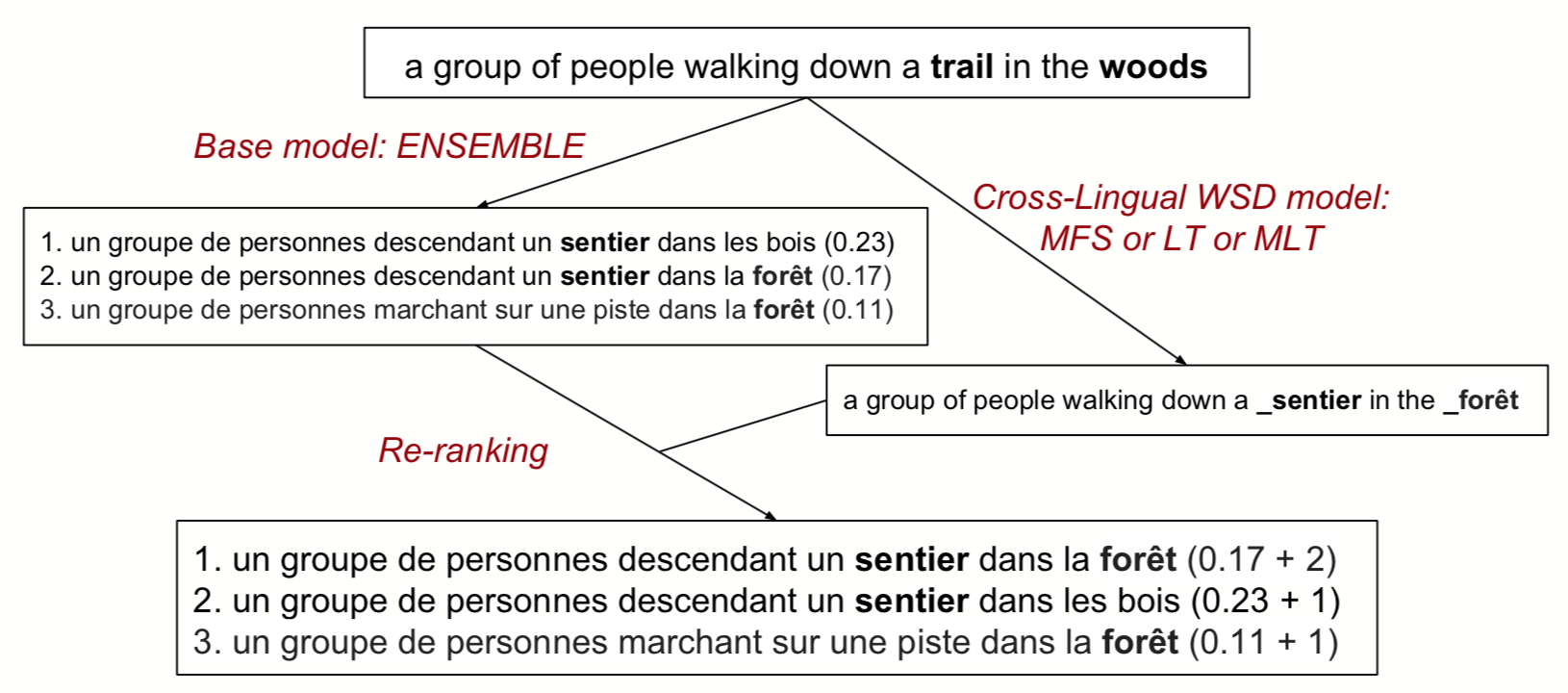
Sheffield Submissions for WMT18 Multimodal Translation Shared Task
Conference on Machine Translation (WMT), 2018

Findings of the Third Shared Task on Multimodal Machine Translation
Conference on Machine Translation (WMT), 2018

End-to-end Image Captioning Exploits Multimodal Distributional Similarity
British Machine Vision Conference (BVMC), 2018
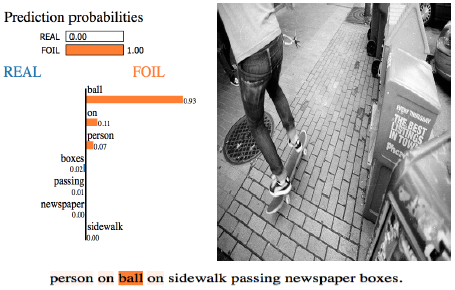
Defoiling Foiled Image Captions
North American Chapter of the Association of Computational Linguistics: Human Language Technology (NAACL HLT), Short Paper, 2018
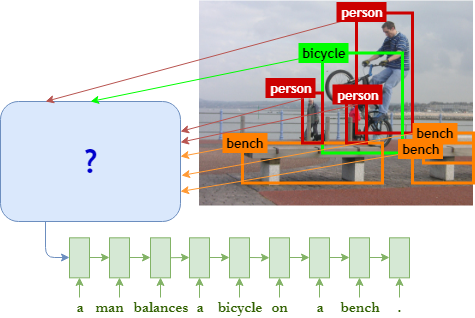
Object Counts! Bringing Explicit Detections Back into Image Captioning
North American Chapter of the Association of Computational Linguistics: Human Language Technology (NAACL HLT), Long Paper, 2018
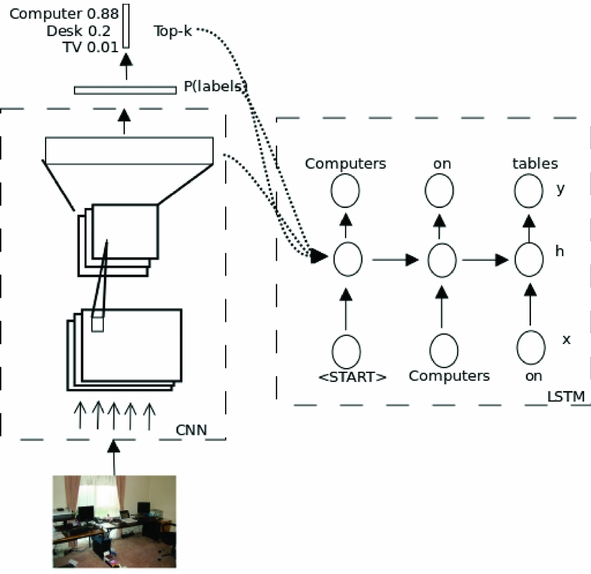
The Role of Image Representations in Vision to Language Tasks
Natural Language Engineering, 24 (3): 415-439, 2018

Multimodal Lexical Translation
Language Resources and Evaluation Conference (LREC), 2018
Exploring the Use of Acoustic Embeddings in Neural Machine Translation
Automatic Speech Recognition and Understanding Workshop (ASRUW), 2017
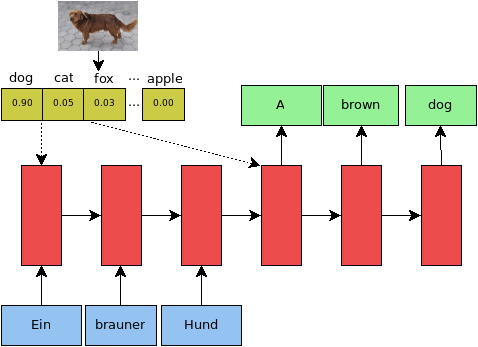
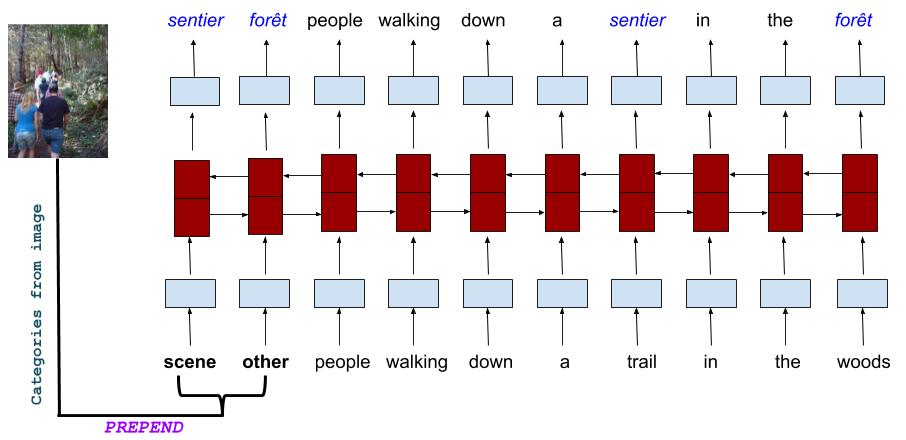
Sheffield MultiMT: Using Object Posterior Predictions for Multimodal Machine Translation
Conference on Machine Translation (WMT), 2017
We participated in the Multimodal Machine Translation (MMT) shared task of translating image descriptions from English to German/French given the corresponding image. Can the use of object posterior predictions instead of lower-level image features help MMT?
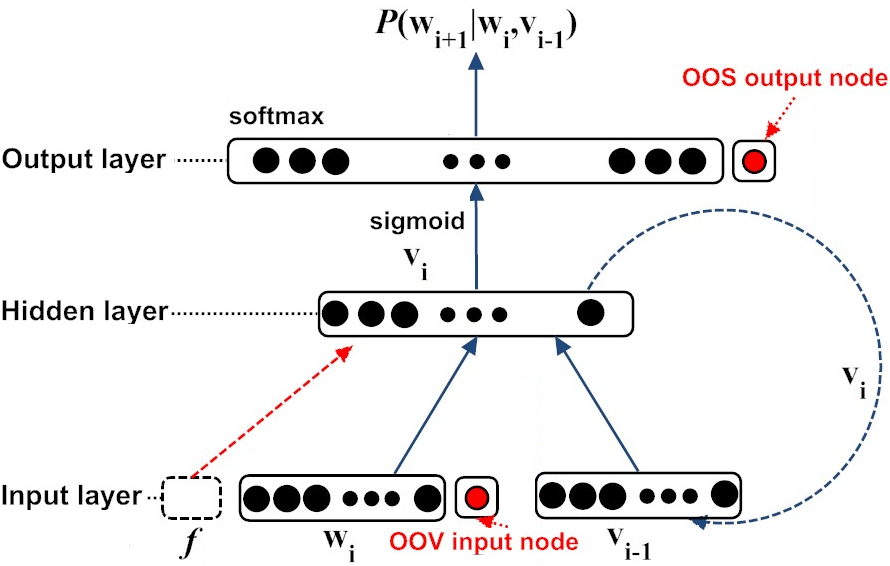
Semi-supervised Adaptation of RNNLMs by Fine-tuning with Domain-specific Auxiliary Features
Interspeech, 2017
How do we fine-tune RNN Language Models with auxiliary features for a specific domain?
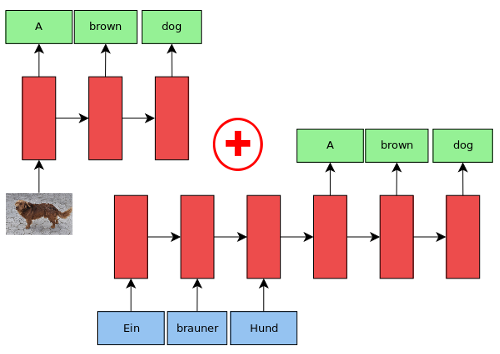
European Association for Machine Translation (EAMT), 2017
What are the contributions of image captioning and neural machine translation systems in Multimodal Machine Translation? Can we use the output of image captioning systems to rerank neural machine translation hypotheses?
Contact
For project/collaboration related queries, please contact Prof. Lucia Specia.
For website related issues please contact Josiah Wang.